It Was Fine to First Pick Green Commons, Actually#
March 4, 2025
The public draft data for Aetherdrift dropped recently, giving us a chance to dive into the details of how people drafted and answer some pressing questions. The story of Aetherdrift so far is the dominance of the color green, and whenever there is one color dominating the performance metrics, the question arises of whether to believe those numbers, to draft middling commons in that color early, or to continue prioritizing strong rares and early picks in underperforming colors.
A refrain I’ve observed throughout this format is the idea that “the data is misleading”, that is, that the overall strength of green lends an amount of extra win rate to green commons that amounts to bias – if you force your way into green before seeing premium cards, you shouldn’t expect the same results as if you were to find your way in the honest way, by taking powerful cards in whatever colors appear (many of them presumably green), then collecting commons in your open lane. There’s some obvious truth to this advice, but how does it stack up against the data?
We’re going to test it using analysis I recently developed to empirically judge card quality metrics at their effectiveness in guiding P1P1 decisions. The way that analysis works is by ranking the cards in the opening pack of each draft, identifying the highest ranked card according to the metric, and replacing the results of that draft with the average results of a draft by the a player of similar skill who chose the identified card P1P1. For the details and results of that analysis, please see this article.
The metrics that performed best in that analysis were DEq, my custom card quality metric, and GIH WR, the 17Lands standby and community standard. For the new format, we have about two weeks of data, so I chose to focus on the viability of relying on the very first data release to draft over the remaining days in the data set. Specifically, I looked at GIH WR and DEq as they would have appeared on the third morning of the format, and simulated the effects of drafting using those rankings, unchanged, from that day through February 25 to make all P1P1 choices.
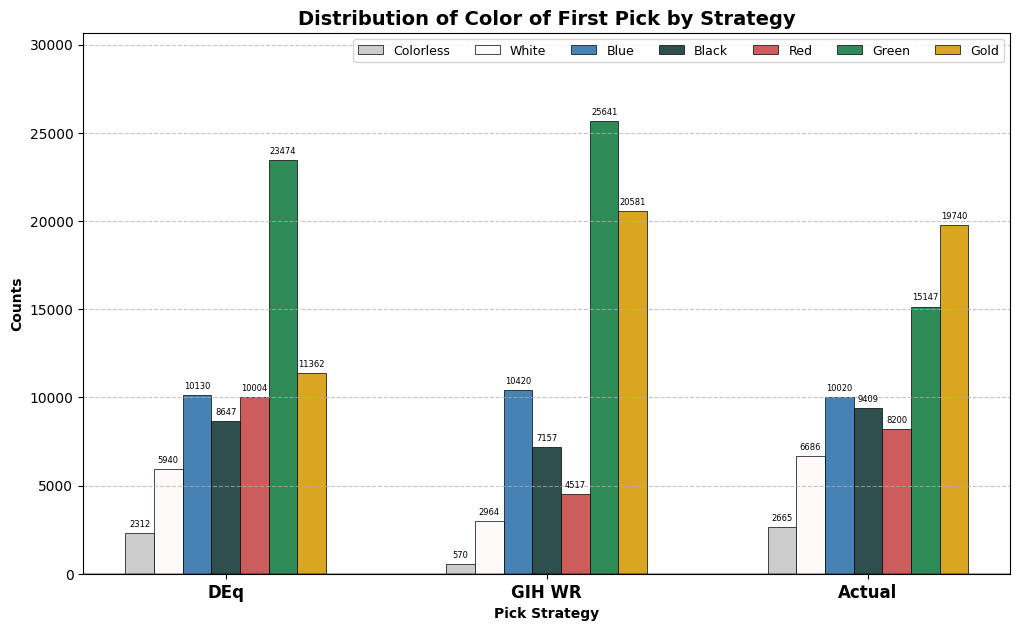
Broadly, the metrics performed identically, on average yielding results about 0.25% greater than those achieved in the actual results, although we will see that they recommended very different cards in many circumstances, and DEq did a better job at replicating the strategies of top (and bottom) players. Because there was no gap in performance, I won’t dwell on the differences between the metrics in this analysis, but instead what they have in common: an emphasis on drafting the best-performing color, green. Let’s take a look at the broad results in a few tables. First, the pick frequencies by color. The chart will show three groups of bars, indicating three different distributions of first picks by color. For the two metrics, the distribution will reflect how often a card of that color was the highest-ranked in the pack.
Under our simulated strategies, that will be the color distribution of the first picks. The actual distribution of first picks by color is shown alongside.
from deq.dft_early import *
counts_bars()
GT(count_totals).tab_header(
title="Total Observations", subtitle="Days 3 Through 14").fmt_integer()
| Total Observations | |
| Days 3 Through 14 | |
| Drafts | Matches |
|---|---|
| 71,868 | 362,457 |
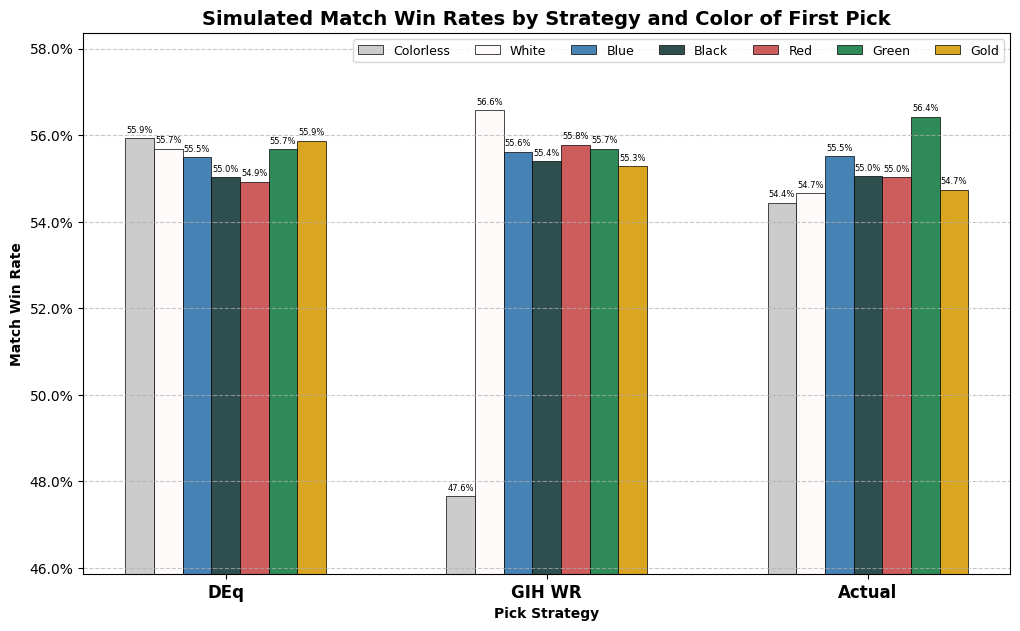
What stands out is the large number of green cards identified by DEq and GIH WR. Out of 71,868 opening packs, GIH WR picks a green card as the highest ranked card in 25,641 of them, over 35%, and DEq is just behind with 23,474. Actual drafters took green cards with “only” 15,147 of their first picks. Next, we will look at the win rates simulated or achieved for the various groups. Should we expect green to underperform when we are less selective? The height of the bar will show the win rates for the picks selected by that strategy for that color, and the overall win rate, properly weighted, will appear in the table below.
wr_bars()
GT(total_win_rates).fmt_percent().tab_header(
title="Simulated Match Win Rate", subtitle="by Strategy")
| Simulated Match Win Rate | ||
| by Strategy | ||
| DEq | GIH WR | Actual |
|---|---|---|
| 55.51% | 55.51% | 55.26% |
While I’d love to dive into every nook and cranny of this analysis, we’ll keep it focused on the question of green: the broad implication is that the performance metrics want you to be drafting a lot more of it, and are likely justified in doing so: in the actual results, people did much better when they started with a green card than any other color, on average, and according to the analysis, even by lowering the quality of green first picks by taking a lot more of them, you still can be expected to end up with an above-average win rate. The 55.7% win rate simulated for GIH WR and DEq by taking green cards at the rate suggested is higher than the win rate observed in the actual results for all non-green first picks. Remember, those are results derived from observing first-picks of the specific cards identified by the day two metrics, in the specific frequencies observed, by players of similar skill.
Draft the best color more often in the early format.
You don’t have to be terrified of the color drying up from one day to the next. I recall seeing chatter on day three of people being afraid of green already being cut off; twelve days later, green drafters were still having a better time of it than anyone else.
Let’s dive in to the specific question of commons, because I think that’s where most of the controversy is. Yes, we’re going to be taking Worldwagon and presumably Autarch Mammoth first, but should we be taking Hazard of the Dunes P1P1? Rampaging Ketradon? Broken Wings? While I can’t answer for sure, I think the data suggests that it was probably fine to do so for quite a few days into the early format, depending on circumstances of course. Let’s break it down. First let’s look at the underlying stats driving the selection process.
GT(common_ratings.sort("DEq", descending=True)).fmt_percent(
columns=['DEq'], force_sign=True).fmt_percent(
columns=["GIH WR"]).tab_header(
title="Day 2 Metrics", subtitle="Green Commons")
| Day 2 Metrics | ||
| Green Commons | ||
| Name | DEq | GIH WR |
|---|---|---|
| Run Over | +3.48% | 60.35% |
| Stampeding Scurryfoot | +2.66% | 60.68% |
| Hazard of the Dunes | +2.21% | 59.72% |
| Migrating Ketradon | +1.57% | 60.82% |
| Venomsac Lagac | +1.46% | 58.44% |
| Pothole Mole | +1.40% | 60.07% |
| Jibbirik Omnivore | +0.76% | 58.36% |
| Beastrider Vanguard | +0.53% | 58.82% |
| Veloheart Bike | −0.11% | 56.46% |
| Broken Wings | −0.20% | 57.22% |
| Silken Strength | −0.44% | 55.58% |
| Bestow Greatness | −0.50% | 56.25% |
| Loxodon Surveyor | −0.63% | 56.05% |
| Alacrian Jaguar | −0.77% | 54.04% |
Remember, these are the day two metrics. Things changed a lot over the ensuing days, but these are the values we are stuck with for our analysis. So far I haven’t emphasized the differences between DEq and GIH WR, but with some concrete examples in hand we should attempt to explain why they don’t agree.
DEq estimates the value attributable to a draft pick based on where it was picked and what happened in the event overall, specifically using ATA, or average pick order, the maindeck rate, GP%, and the corresponding win rate stat GP WR. As a result, DEq boosts highly-picked and frequently-played cards quite a bit relative to GIH WR, which is one of the reasons it performs much better in matching the distribution of how top players draft.
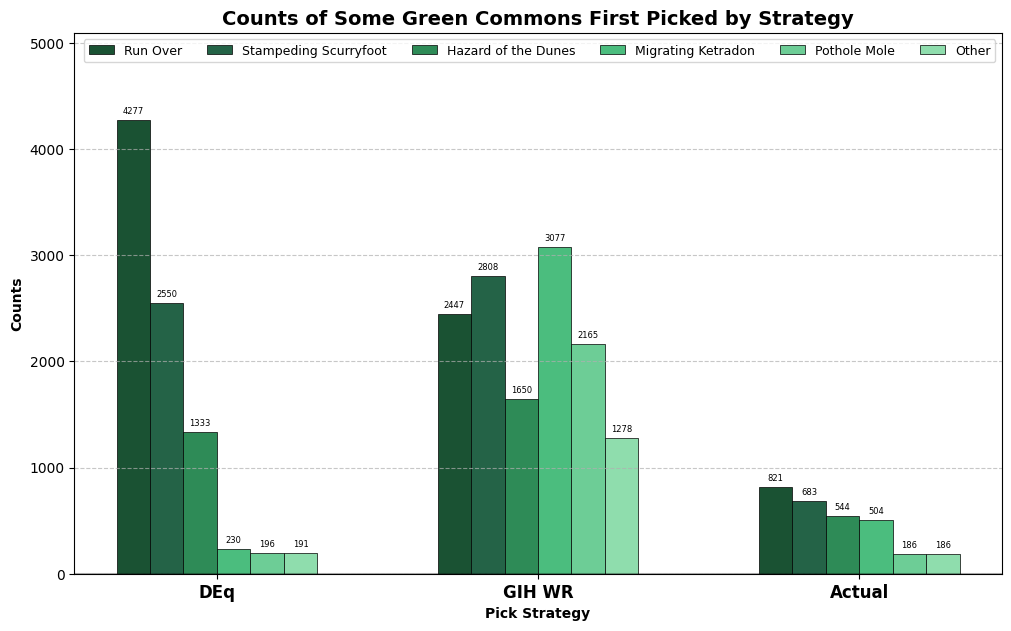
GIH WR uses in-game data, which gives some additional signal related to card impact and effectiveness, but also introduces some biases. In particular, GIH WR is biased towards cards that fit into controlling decks, so Ketradon and Mole are boosted relative to the other green commons which are a bit more conducive to wrapping a game up. When we look at the substitution analysis, we should expect to see GIH WR drafting lots of Ketradons and DEq drafting lots of Run Overs and Scurryfoots. Let’s take a look. We’ll take a look at the same pick frequency table, narrowed down to green commons only.
common_counts_bar()
GT(common_counts.sum()).tab_header(
title="Green Common Pick Counts", subtitle="by Strategy"
).cols_hide('common').fmt_integer()
| Green Common Pick Counts | ||
| by Strategy | ||
| DEq | GIH WR | Actual |
|---|---|---|
| 8,777 | 13,425 | 2,924 |
Hopefully this chart makes sense in light of the rankings above. DEq is largely reflecting the shape of the actual picks due to its use of pick order data, but with an exaggerated shape since it is following a hard-and-fast rule rather than the loose preferences of actual drafters. GIH WR, on the other hand, is just going ham on every green common in sight. 13,425 is a lot of drafts! There are about 72,000 in the whole dataset, so GIH WR wanted you first-picking a green common in almost one in five drafts. In fact, the difference of over 4500 is over double the difference between the two strategies for the color as a whole, so DEq makes up some of that ground with uncommons and rares, presumably highly-picked ones.
The final piece of the puzzle is the results, but first let’s recall a bit of the methodology. The results in the “simulated” strategy are derived from actual observed results when a player of similar skill took the observed card. But take a look at those actual draft counts: when we are simulating the win rate for the 2165 selections of Pothole Mole by GIH WR, we are relying on a mere 186 observations, distributed across 13 different skill cohorts. There might be 1000 games in that set, but still it’s not a large sample size. The 4,277 selections of Run Over by DEq, on the other hand, are supported by the data collected in 821 actual observations.
Next, the results we are comparing to aren’t going to be those actual results represented on the right. We don’t want to know how people actually did when they took green commons, we want to know how they did instead of taking green commons. So for the 8,777 packs where DEq wants to first-pick a green common, we will take a look at the results of those drafts (whether or not they took the card in question), and similarly for the 13,425 drafts where GIH WR wants to first-pick a green common, we will look at the actual results of those. Let’s take a look.
common_results_bar()
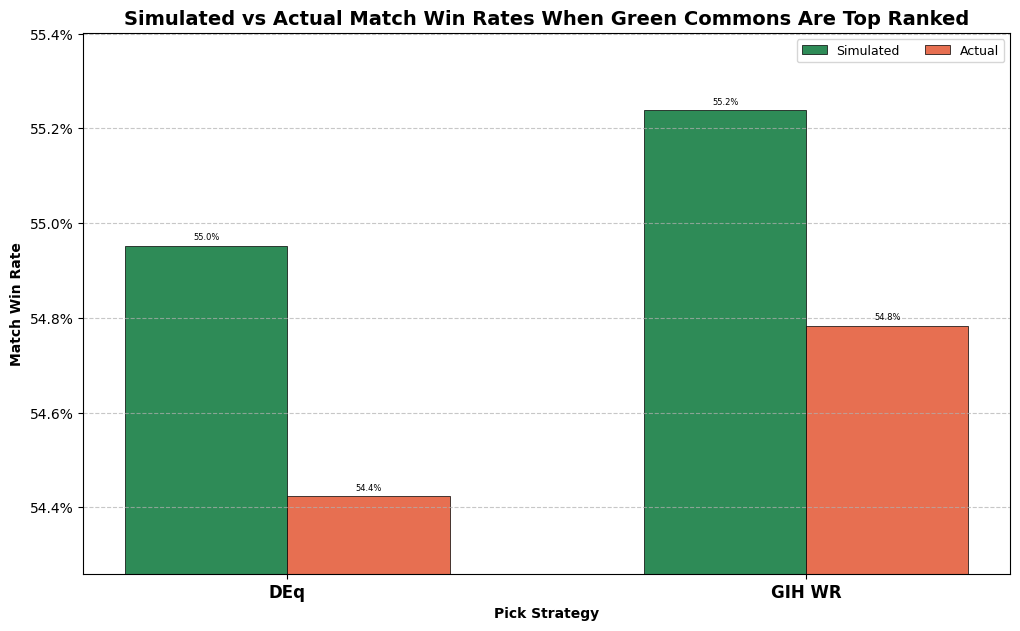
Both DEq and GIH WR project a boost in win rate of at least 0.4% from this slice of the strategy. So the analysis suggests a certain amount of common-grabbing was justifiable in the early format. Note that those comparison win-rates are well below the overall observed mean of 55.26%. This is because, well, as highly ranked as green commons might be, they aren’t as high as Sab-Sunen or even Perilous Snare, so whatever alternatives the observed players had, they didn’t include the best rares in the set. And DEq, being more selective, also narrows in on a lower-quality set of packs overall. As for how intensely you should believe this result, it’s difficult for me to quantify the degree to which the result is statistically significant, given the complexity of the analysis. I certainly think examples like the Pothole Mole make the GIH WR result a bit dubious, but I think the overall picture is fairly convincing.
First picking green commons was fine, actually.
Before we wrap up, let’s take a quick look at how these win rates evolved over the days in our sample. Was it the case that there was a massive edge to be gained in the first few days which rapidly dried up? Let’s take a quick look at the overall match win rate when first-picking the five premium green commons by day, compared to the win rate observed when the cards in question were top-ranked by DEq.
by_day_plot()
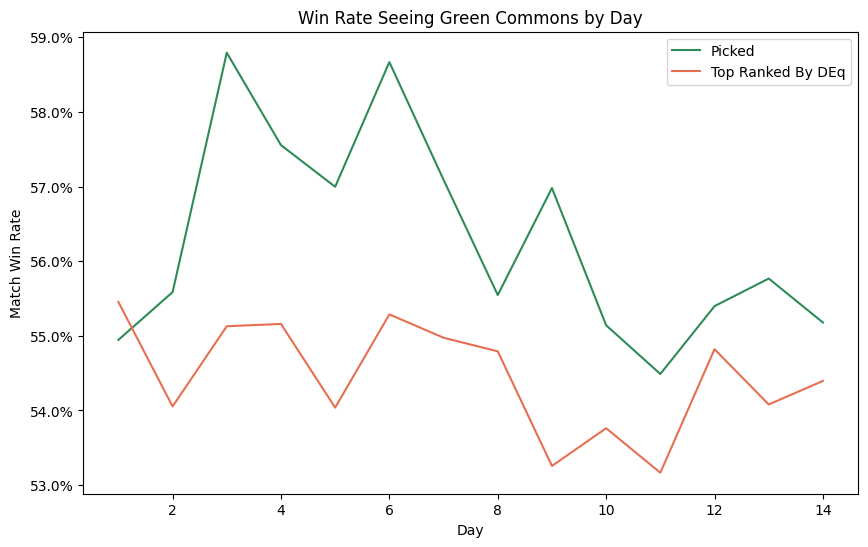
Indeed, the graph shows a clear decline, but the overall picture does nothing to disturb our conclusion. At no point is it clear that the DEq metric erred in suggesting a green common as the pick.
Well, I can’t think of anything else to say on this topic, so I’ll leave it at that. If you have any questions or suggestions for additional analysis, please reach out! As always, deepest thanks to the team at 17Lands for providing this data. Please support their work! The code for the analysis in this notebook can be found on my github.